A Multiverse Reanalysis of Likert-Type Responses
Abstract
There is no consensus on how to best analyze responses to single Likert items. Therefore, studies involving Likert-type responses can be perceived as untrustworthy by researchers who disagree with the particular statistical analysis method used. We report a multiverse reanalysis of such a study, consisting of nine different statistical analyses. The conclusions are consistent with the previously reported findings, and are remarkably robust to the choice of statistical analysis.
Author Keywords
Likert data; explorable explanation; multiverse analysis.
ACM Classification Keywords
H5.2 User Interfaces: Evaluation/Methodology
General Terms
Human Factors; Design; Experimentation; Measurement.
Introduction
In 2014, Tal and Wansink
However, these results are based on Likert-type responses, which are known to be tricky to analyze, as there is currently no consensus on how to best analyze this type of data. Tal and Wansink
Our reporting approach which combines the principle of multiverse analysis
Dataset and Questions
Dragicevic and Jansen's
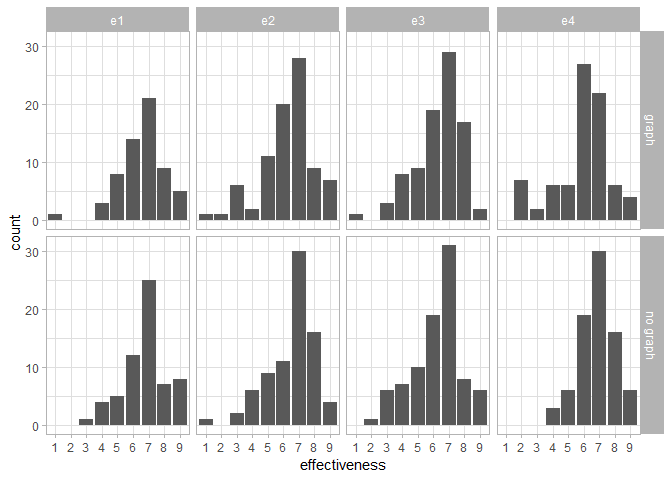
Figure 1 shows the distribution of the raw data. Our question is whether there is an overall difference between graph and no_graph, for each of the four experiments (e1 to e4). We answer this question using nine different statistical analyses, whose results are summarized in the next section.
Summary of Results
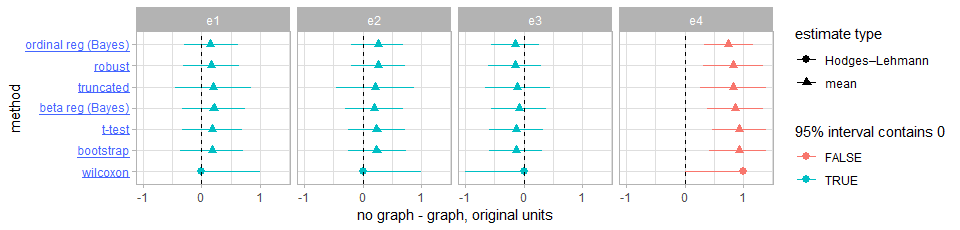
Seven of the nine methods provide us with a point estimate and a 95% interval estimate of the average difference between the two conditions, all summarized in Figure 2. The remaining two procedures provide estimates as a log-odds ratio, shown in Figure 3 (for beta regression, this is the log of the ratio of the odds of going from one extreme of the scale to the other between the two conditions; for ordinal regression, this is the log of the ratio of the odds of going from one category on the scale to any category above it between the two conditions; 0 indicates equal odds). On both figures, red intervals are statistically significant at the .05 level, while blue intervals are non-significant.
Click on an analysis label to see its details in the next section. The complete source code of all analyses is available at R/analysis.html.

Analysis Details
Tal and Wansink
The point estimate of the mean difference and its 95% confidence interval are reported in Figure 2, for each of the four experiments (row labeled ttest). According to the t-tests, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph, p=.00013). The point estimate of the mean difference and its 95% confidence interval are reported in Figure 2, for each of the four experiments (row labeled bootstrap). According to the bootstrap procedure, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph). The point estimate of the mean difference and its 95% confidence interval are reported in Figure 2, for each of the four experiments (row labeled wilcoxon). According to the Wilcoxon tests, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph, p=.00040). The log-odds ratio and its 95% confidence interval are reported in Figure 3, for each of the four experiments (first row). According to the beta regressions, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph, p=.00017). The point estimate of the mean difference and its 95% posterior quantile interval are reported in Figure 2, for each of the four experiments (row labeled beta reg (Bayes)). According to the beta regressions, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph). The log-odds ratio and its 95% confidence interval are reported in Figure 3, for each of the four experiments (second row). According to the ordinal regressions, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph, p=.00040). The point estimate of the mean difference and its 95% posterior quantile interval are reported in Figure 2, for each of the four experiments (row labeled ordinal reg (Bayes)). According to the ordinal regressions, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph). The point estimate of the mean difference and its 95% confidence interval are reported in Figure 2, for each of the four experiments (row labeled robust). According to the robust linear regressions, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph, p=.00016). The point estimate of the mean difference and its 95% confidence interval are reported in Figure 2, for each of the four experiments (row labeled truncated). According to the truncated normal regressions, there is no evidence for a difference on average between graph and no_graph, except for experiment 4, for which there is strong evidence for an effect in the opposite direction (no_graph more persuasive than graph, p=.00037).
For information on any of the other eight statistical analyses we conducted, click on its label on Figure 2 or Figure 3.
Discussion
However we analyze the data, the substantive conclusions are about the same. While the Wilcoxon estimates and intervals in Figure 1 look different from the other estimates, it is estimating a slightly different quantity: a median of the differences instead of a difference in means (as the other approaches in Figure 2 are). In Figure 3, while the two rows are both on the log odds scale, they are measuring log odds ratios of different things, so it is hard to compare the values directly. Since the ordinal regression measures the log odds ratio of an increase from one category to any category above it, we should expect this value to be larger than the estimate from the beta regression, which measures the log odds ratio of going from one extreme of the scale to the other (a less likely event). With smaller sample sizes, it is likely that the results would have differed more.
From this multiverse analysis, we can conclude that our results are very robust, and not strongly sensitive to the choice of analysis method: if the conclusions of Dragicevic and Jansen
Our reporting approach, which combines the principle of multiverse analysis